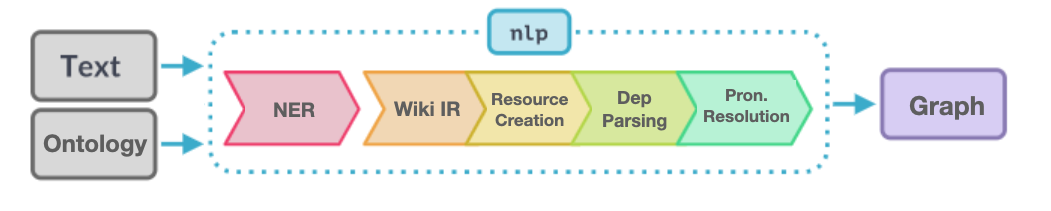
An automatic pipeline to construct an RDF-star graph from texts
textToRDFGraph project aims to develop an automatic information retrieval pipeline based on Natural Language Processing and Semantic Web technologies to construct a knowledge graph from textual data. It explores how we can extract named entities from texts to create linked open data networks and then use the open network data to extract more information from texts and unify the resources representing identical entities retrieved from texts in different languages. The primary purpose of this project is thus to construct a graph from textual information that can be queried for the embedded references in texts regardless of the text language. A high-performing query requires the data to be stored in an optimized way with all the metadata about extracted statements necessary for a faithful citation and reliable representation of data and metadata. Using RDF-star technology in graph construction carries this objective; therefore, this project shows how to use this technology to comprehensively represent textual data and facilitate complex queries required for humanities research.
State of Research:
This research project in the field of Digital Humanities (DH) focuses on employing Natural Language Processing (NLP), Semantic Web technology, and Linked Open Data (LOD) principles for an optimized retrieval, storage, and query of information present in natural language texts. The outcome editions and data model, as well as tools and techniques developed for this project, will be of interest to scholars in the fields of Digital Humanities, Computational Linguistics, History, History of Science, and History of Economy.
Automated extraction of information from texts and its transformation into machine-readable data enables efficient query of information and linkage of atoms of knowledge. Strategies have been presented for extraction and linking named entities from texts with knowledge graph individuals and their association with grammatical units that lead to producing more coherent facts (Martinez-Rodriguez et al. 2018, p.339). These strategies rely on approaches using Information Extraction to populate the Semantic Web and/or using Semantic Web resources to improve Information Extraction (Martinez-Rodriguez et al. 2016). Projects like LODifier take the unilateral approach to populate a knowledge graph based on the automatic extraction of named entities and their relations from unstructured English texts (Augenstein et al., 2012). This project, however, takes a bilateral approach; i.e., it aims at developing an NLP pipeline to extract named entities (such as persons and locations) and their relations from texts in multiple languages (initially English, German, and Persian) to construct a knowledge graph. This pipeline then enriches the graph with additional information about the named entities available on open knowledge repositories (such as WikiData) which are then used to retrieve more information from texts based on grammatical structures. This pipeline would thus result in a network of resources representing named entities and documents with machine-readable content in different languages that might have references in common. As a result, the text resources would be queryable by references, irrespective of the language of the text.
This project will take a new approach using the RDF-star technology regarding the knowledge graph construction. Successful digital editions, such as Bernoulli-Euler-Online BEOL and LetterSampo, have been created using the standard RDF enabling users to study the editions as a network of interconnected resources and to query the data using the standard SPARQL. Standard RDF, however, is not an optimal choice for the digital edition of metadata-oriented documents such as travel journals because most of the information in such documents is accompanied by metadata information describing it. For example, according to source S1, “person A was at location B” for a certain period (e.g., from the 1st to 10th of July 1684); the source document and the duration are metadata information that must be preserved. RDF statements should be created to add the metadata information to the RDF statement representing the central fact. This is troublesome using the standard RDF. The first RDF 1.0 specification uses a reification mechanism for supporting statements about statements. Reification, however, introduces processing overhead due to the increased number of additional statements needed to identify the reference triple and appears too verbose when represented in RDF and SPARQL (Kasenchak et al. 2021). RDF-star and SPARQL-star overcome this deficit with an extension of the RDF standard and increase the efficiency of queries by reducing the query time. RDF-star allows a triple to represent metadata about another triple by directly using this other triple as its subject or object (Hartig 2017). Using RDF-star, we can easily attach metadata to the edges of the knowledge graph, as shown in the following figure:
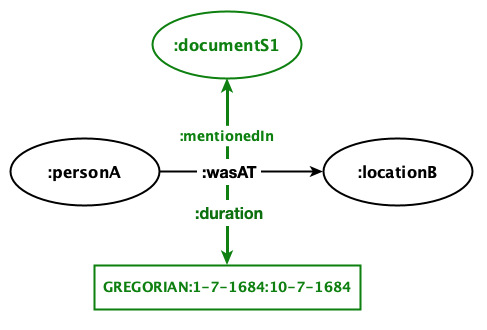
Thus, the NLP pipeline developed for this project will not only extract information from texts to construct a knowledge
graph, but it will also add the source of information to the edges of the graph, which will be essential for citation
purposes. Considering this example, through SPARQL-star, users can query, “Where was personA on 6.7.1684?” The answer
would be locationB, as mentioned in documentS1.
The example above illustrates a simple use-case of RDF-star; it can, however, represent more complex data structures. This project will present the first actual application of this technology on humanities data to generate digital editions. This project is the only one currently attempting this because it would require defining entirely RDF-star-based ontologies and implementing tools based on SPARQL-star to analyze graphs.
Alassi (2023) presented the early stage of this NLP pipeline in a peer-reviewed proceeding of DH2023 that received supportive reviews, e.g. (score: 98 out of 100):
The author proposes to create RDF-star-based open research data from textual contents using automated text extraction methods. This work is highly relevant [to DH field], as it enables the machine-readable processing of textual contents using standardized vocabularies and semantic web technologies.
Similarly, the paper containing the preliminary idea received positive feedback from reviewers of DH2022; for example: (review score: 100 out of 100)
This contribution can play an important role in bringing the arguably more complicated structure of humanities’ hermeneutics into dialogue with methods and technologies for asserting facts. RDF* and SPARQL* have been around as technologies for a while, but there is a lack of expositions of how to apply them in the digital humanities and of actual use cases. Integrating this approach to data modeling and tooling with established DH platforms is a venture, the experiences, and results of which are bound to be interesting for both methodological reflection and tool-making in the DH domain.