Pipeline
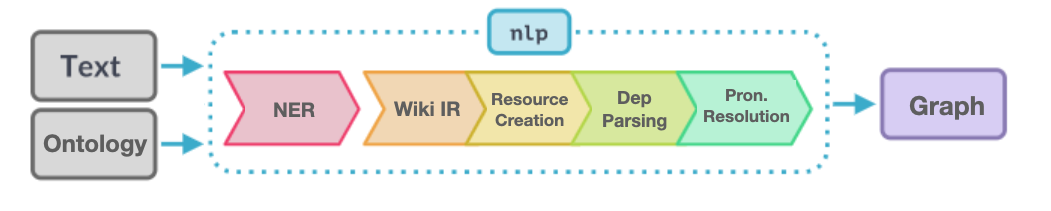
The pipeline extracts the named entities and the relations between them from texts to augment a knowledge graph. The pipeline focuses on extracting and linking three types of entries from unstructured texts in different languages: locations, persons, and their relations. Based on the language of the input text, the pipeline will be initialized with a pre-trained statistical language model. Based on the input ontology, the pipeline will extract information from the input texts in different languages and will construct the output graph, that is an RDF-star-based graph with the source of the extracted information added to the edges of the graph.
Inputs:
- path to a .txt file containing text or path to a folder containing multiple text files. At these first stage of the development, the pipeline accepts only English, German, and Farsi texts.
- path to the ontology file and corresponding SHACL shapes file. From the ontology and SHACL shapes, the pipeline extracts types of entities that should be extracted, and their relations.
Read more about the inputs of pipeline here!
User can choose between spaCy and Flair libraries to be used for the NER (Named Entity Recognition) pipe. If spaCy is chose, large English or German language models is used for processing the input text. To process texts in Farsi, Flair is used. The pipeline uses spaCy’s POS-tagging and dependency parsing results, to parse the relations between entities.
The pipeline consists of two main stages:
Stage 1: Initial construction of the graph
This stage is consisted of three pipes:
- Named Entity Recognition (NER): based on the language of the text, the mentioned named entities (persons and locations) are tagged within the text. In ambiguous cases, information from the surrounding context in which the particular mention occurs can be used to infer which individual or location a mention refers to using co-occurrence metrics of a pair of entities and content information (Stoffel et al., 2017). The algorithm lists possible resolutions for the ambiguous entity allowing the user to choose the right one or tag the entity manually.
-
WikiData Information Retrieval (Wiki IR): based on the ontology, for each tagged entity, the main properties specified within the ontology are retrieved from WikiData. In case of multiple records on WikiData, the algorithm will ask the user to choose the correct option. In case of no record on the WikiData for an entity, the user can add the missing information. The following information is retrieved for the tagged entities:
a. Person: name, date of birth, GND number, gender, link to the Wiki record.
b. Location: name, Geoname-ID, link to the Wiki record.
- Resource Creation: based on the ontology, the retrieved information will be used to create resources for entities. Then GND numbers for persons and Geoname-IDs for locations are used to unify the entities given in different languages. Next, references to entities are replaced in texts with standoff links to the corresponding resources using their IRIs, and documents are then stored with enriched textual bodies. Figure below shows an excerpt of the graph generated by the pipeline for three sample texts in Persian, English, and German that have references to locations and persons in common.
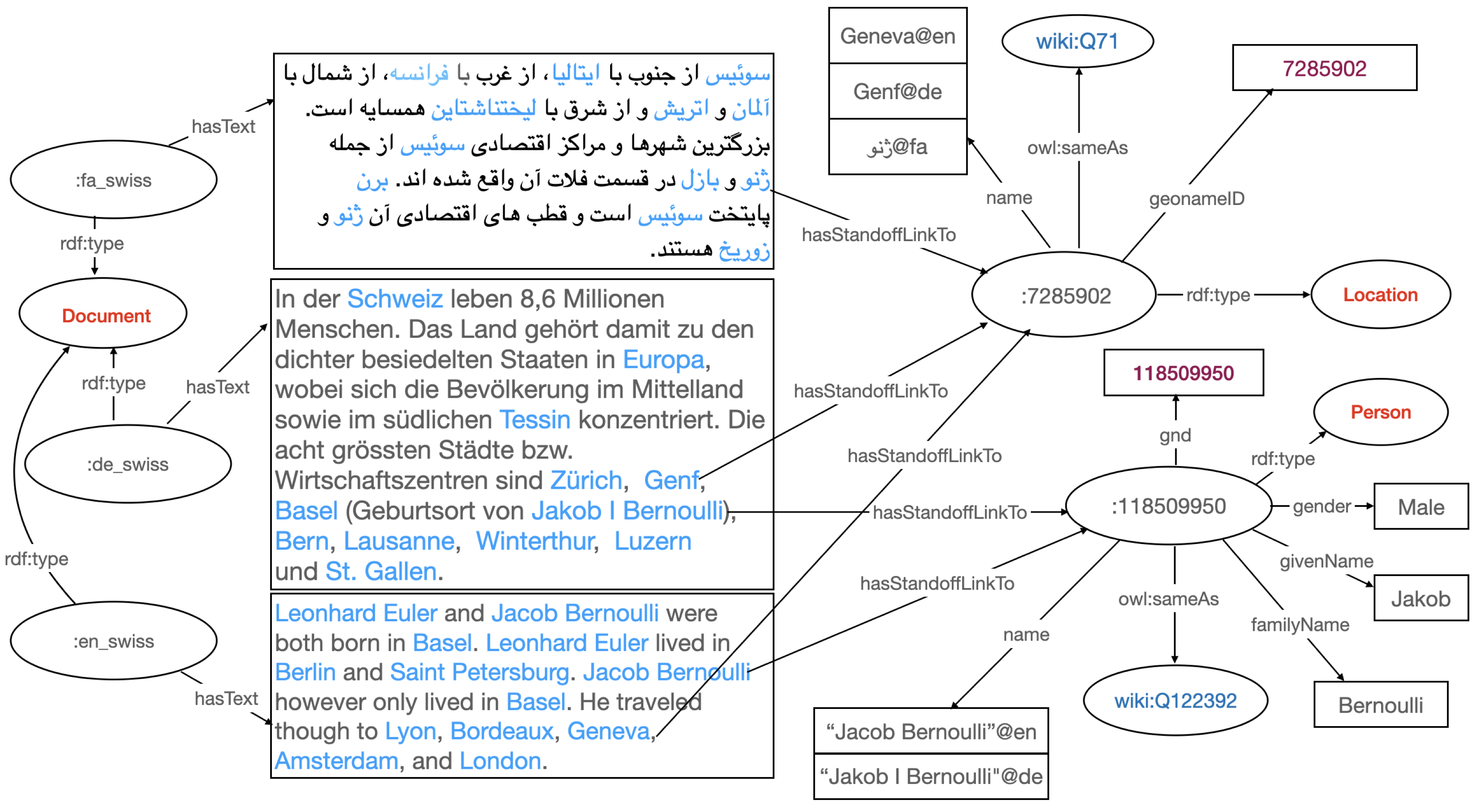
Note: In the stage 1 of the pipeline, a preliminary verification of the constructed graph is performed using SHACL shapes. Thus, at the end of stage 1, a valid graph is constructed containing nodes representing the documents and named entities. The text content of the input files are stored with standoff links to the referenced named entities, as shown in the image above. This allows users to query for all documents, regardless of the language, that contain references to a certain person or location.
Note: The pipeline outputs the extracted named entities with their wiki information and text position details as JSON in the project output directory.
Stage 2: Enriching the graph
- Dependency Parsing: more information about the named entities and their relations can be extracted from the text through dependency parsing and part-of-speech (POS) tagging utilizing the Stanford dependency terminology (de Marneffe, Manning 2016). The definitions of resource classes and predicates and their subject and object class constraints (ranges and domains) defined within the custom ontology and custom SHACL shapes are considered parsing rules.
For example, the predicate
traveledTohas subject typePersonand object typeLocation; thus, only relations are considered where the subject of the sentence is a person entity, the object (or propositional object) is a location entity, and the lemmatized form of the verb istravelis considered. - Pronoun Resolution: the resources representing the named entities found in the text are put in a LIFO stack to be used for the backward resolution of pronouns in the following sentence. If the subject or object of a sentence is a pronoun, the algorithm attempts to resolve it. Thus, to resolve personal pronouns, the nouns in the closest vicinity of the pronoun and the gender information retrieved from WikiData are used. This approach prevents gender bias in state-of-the-art coreference resolution systems (Webster et al., 2018) and does not cause performance tradeoffs. Even though this is an efficient approach for anaphora resolution in English and German texts, other languages like Persian contain zero pronouns (gender-neutral) which cannot be resolved in this way.
Note: Stage 2 of the pipeline can be switched off if the user wishes no relations of named entities to be automatically extracted from input texts.
Note: The extracted relations through the second stage are outputted as Excel stored in the output directory of the project.
After the completion of the second stage, the newly added graph edges are verified through provided SHACL shapes. Then the source of the extracted information is added to the edge of the graph as a metadata represented through RDF-star triples, as shown below:
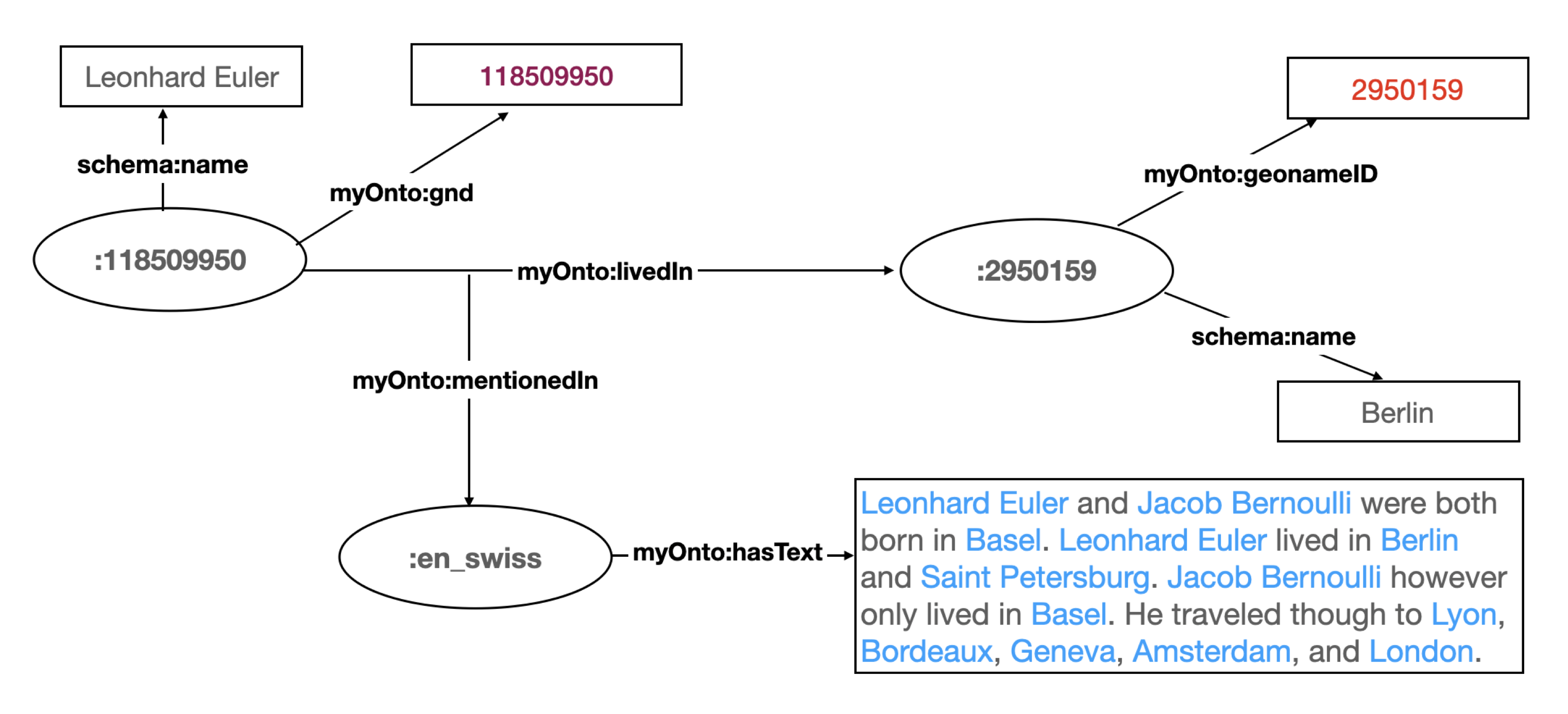
Thus, users can ask for all documents mentioning a specific person or location. For example, a query for texts
mentioning a location with the name Geneva would return all documents in which this location is
referenced in any language Geneva, Genf, ژنو, etc. Furthermore, through SPARQL-star, one can query for documents
containing a particular relationship between entities; for example, the user can ask, “Where did Leonhard Euler live?”
the answer would be Berlin, according to the document en_swiss.
OUTPUT: The pipeline outputs the constructed RDF-star graph serialized in Turtle.